The neglected and meandering history of printing websites
The neglected and meandering history of printing websites
The web has changed a lot since its early days. HTML tags have been discarded (<b>); repurposed (<small>) or added (<canvas>). Thinking has changed with the advent of new technologies (e.g. position:fixed and mobile) and as with any medium, some things have been neglected. Print is one of them.
The role of print has changed with the web. Way back in 2003 the browser print function meant nothing more than “print this website on to a piece of paper”. Its meaning transformed over time.
PDF, an invention from 1993, was slowly incorporated into browser print dialogs, but this itself took time, for instance Windows users had to wait till version 10 was released in 2015 and before that they would have to jump through hoops to set up PDF printers.
As PDFs grew in popularity, the meaning of print on the web changed from print to paper to print to a file I can store on my hard drive.
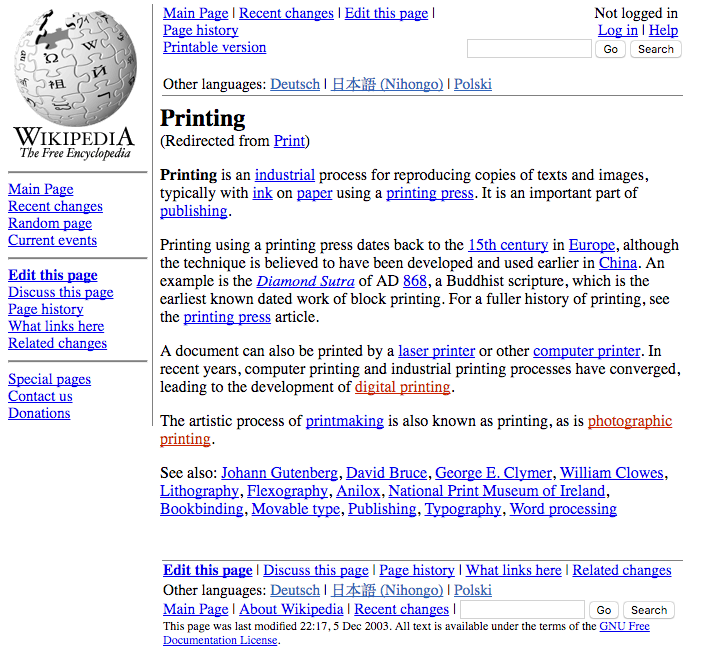
With mobile, this changed again. In 2016, one of the findings of Wikimedia research was that people are increasingly getting information online, then consuming or sharing it offline. Interestingly, the mechanism to deliver a printed artifact, previously used by anyone with a printer, was now being used by people to make content cheaper and more available.
People, especially in areas where internet access is slow or not widely available, use the apps they have installed on their phone to turn content into PDF and then use other apps to share them via the small social networks they have — whether it be WhatsApp, WeChat or Xender. It’s important to remember, that while we are making huge strides in technologies such as Service Workers and the Progressive Web Apps built off them — they do not tend to solve this problem of offline sharing — they only support offline consumption.
Going forward to the present day in 2017, my team got a quite modest engineering problem to solve (or so we thought). The goal was to make it easier for Wikipedia mobile users to print to PDF. It might feel safe to assume that providing a shortcut to download PDFs would be easy. Every browser has a print function. Every browser can print to PDF. Right? Wrong.
The problems with printing
The first thing we set out to do was to upgrade how our printed content looked. Our designer, Nirzar, did some designery magic — working out typefaces, margins, paddings, font sizes and line spacing with the goal of optimising our editors content for the printed medium (which is very different to the needs of a web user) — and came up with a mock. It was beautiful. It was exciting to implement and see how it would look on all our content. However, as always with web development there were things we struggled to do while implementing it.
Wasted whitespace
The print medium is different from the digital medium — a major difference being content is constrained to the physical dimensions of a sheet of paper. In the interest of saving paper, we wanted to have more control over things like the recommended printed size e.g. A4/US Letter. The CSS3 spec has thought about this -paged media — but, alas that’s in draft and barely supported across browser vendors.

There were also times we wanted to minimise paper wastage. We found the page-break-before useful to a certain extent, but it gave undesirable results in certain contexts. We found certain printed page contained much wasted whitespace, but it was difficult to control the threshold — ideally we wanted to break based on the remaining percentage of vertical space of the page. Nothing helped us with this.
Page numbers
We wanted to show page numbers in our table of contents so that our readers would be able to easily jump to appropriate sections in printed copies or if viewing in a viewer that didn’t support links. Not possible. We had to move on.
Broken imagery
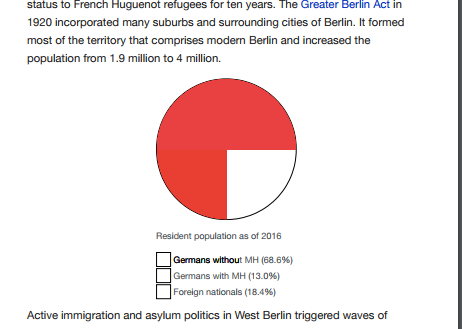
Wikipedia articles are written in wikitext and much of the content is unstructured. It’s created organically by editors over time using the building blocks of the web — HTML. Many articles make use of CSS background colors to convey pieces of information. When used irresponsibly — thoughts of Geocities websites with full screen background graphics come to mind as anti-patterns— it creates a problem in print mode by using valuable printer ink. As a result, many browser vendors optimise for this by stripping background graphics by default. While that is a sane sensible approach, when removing a full screen background, it’s not so useful on a 40px square HTML element that is supposed to be red and is associated with a pie chart for which it acts as the key. Much of our data is optimised for sharing and translation. Many of the diagrams in Wikipedia tend to separate graphic and text so that graphics can be reused across languages, so there is logic in the approach to using HTML and background colors.
A developer could predict this was going to be a problem. If given appropriate APIs the developer could mark up certain elements should always be printed with their backgrounds so the printer would know better, however, no such mechanism is available. Instead, the onus is on the user, to predict this behaviour and find the relevant option in the print dialog interface. Of course, instructions could be left in the web page to explain this, but this is not the early days of the web. We shouldn’t have to.
Sadly, this is the least of things a user needs to be aware of when printing…
Missing content that cannot be loaded
Many websites, Medium and Wikipedia included, lazy load images or other content to save users bandwidth and avoid serving unnecessary wasted bytes. This is great for people who want to dip into content, but not so good for those who want to take a page offline and read at their leisure. The problem we face is that as soon as a user decides to print a page, via the browser’s menu, they have expressed an intent to read all the content and the web page needs to adapt itself quickly to support that. For users without JavaScript we store images inside noscript tags, but there is no equivalent for when inside the print medium. Maybe there should be?
In the real world, to deal with this problem, as a JavaScript engineer we need to detect intent. A request to print via the browser clearly identifies that intent and can be detected by some kind of JavaScript event, but it’s difficult for websites like Medium and Wikipedia to react on when that happens. There are event handlers that allow you to react to events — onbeforeprint is the living standard that was thought of for this purpose. It allows you to inject copyright notices into the content for example. However, Chrome, a browser that has made tremendous progress in other parts of web standards doesn’t implement this (although provides an alternative mechanism for those who want it via matchMedia).
Even though mechanisms exists, the standard doesn’t support a use case such as loading image downloads that have been deferred until later. The onbeforeprint event like all JavaScript events are fired synchronously. The retrieval and display of multiple images is an asynchronous activity which requires communicating with web servers and downloading responses. It’s impossible to print such a page as PDF with all its images. The issue is interesting with various challenges (now encapsulated in a bug against the HTML spec) — how long of a delay is acceptable?; How would you deal with images that do not load?; What if asynchronous functions fail? The problem is unlikely to be solved for some time.
Clumsy operating system UIs
The solution to dealing with “missing” content seemed trivial at first glance if you use a print button in the UI. The click handler for that button, can make use of the window.print method, calling it only when the page is ready (when images are loaded). There would be no need for feature detection, as pointed out earlier — printing is pretty old school JavaScript. 🐵
I was getting ready to code a solution, but then our designer, pointed out that the printing experience on iOS is pretty poor. In iOS it looks for local printers on your WiFi and provides no PDF option. Unfortunately, printing to PDFs is usually bundled in within the printer dialog and sometimes extremely hidden away without any way to guide the user. For this reason he wanted me to restrict our download mode to the Android platform which appeared to be better optimised for PDF downloading. 🙉
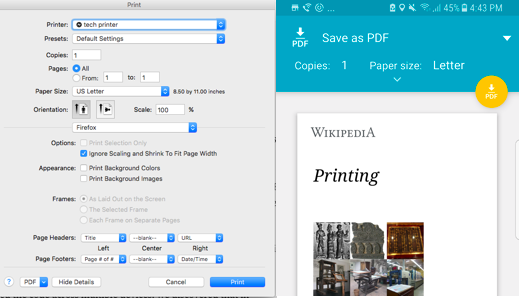
Like most developers, I hate browser detection. Browser detection always feels like a last resort, but I could see Nirzar’s point. It left a bitter taste in my mouth. It seemed like a missed opportunity. Imagine a world where I could provide parameters to the print function like so:
// potential API one
window.print('pdf', { size: 'A4' } );
// potential other API
window.printPDF()
Sadly no API exists. 🙈
As someone who scrunches their face at any attempt of browser detection I bit my tongue and said okay, but I managed to relax the requirements to only blacklist the iOS platform. I thought that would be enough and then at least our desktop users could also use the function.
I should have known better. Frontend development is a maze of woes.
window.print is a lie!
I’ve been coding for many many years and the window.print JavaScript function was probably one of the first methods I played with. It was important in my early days of learning JavaScript. It helped me grasp concepts such as progressive enhancement. Printing needed JavaScript, so you needed to think about how to prevent a useless button showing when JavaScript wasn’t available. To solve this of course, there are many approaches. A print button could be accompanied with a <noscript> underneath apologizing profusely for failing to provide a service. Alternative you could create the button via JavaScript. This was an early, enlightening example of strategies and trade offs that I would wrestle with later in my life as a software engineer.
As we tested our newly built simple download button across multiple devices, we discovered that in various browsers the button did nothing. Even if you clicked it multiple times!
The function exists in pretty much all browsers, but as my team discovered while debugging this problem, calling it in many Android mobile browsers does not invoke the print interface.
Unexpected things happen when you call window.print() on a mobile browser:
- Opera on Android has abandoned printing via the browser altogether — it instead has a feature called “offline pages”. Its window.print function appears to be a no operation (NOOP).
- In UC Browser and Dolphin, similarly window.print is a NOOP. These browsers have abandoned the print function altogether — you cannot even print via the menu. If you want to print to PDF these browsers are not your friend.
- In Firefox, calling window.print() throws an exception. This is somewhat useful, but since window.print in the happy path loads the print dialog it doesn’t make this easy to feature detect before you render a print button. At the very least, we are able to show a message saying “Your browser does not support printing”, but that’s a lousy user experience.
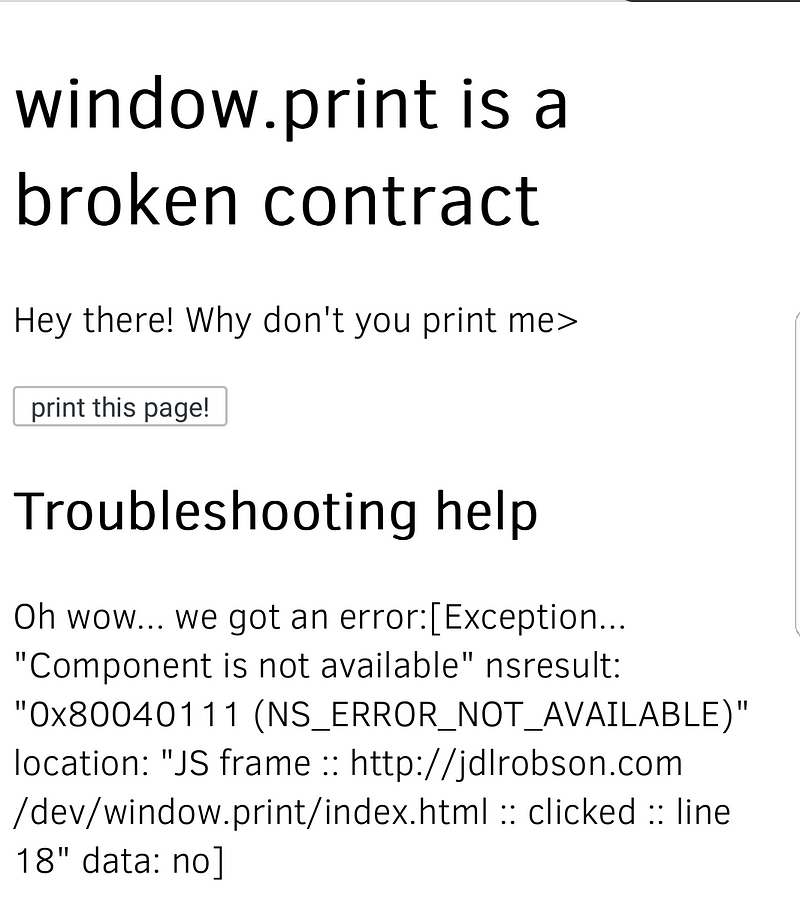
You can explore how these browsers behave and others that I’ve not listed using this minimum test case I wrote.
All this would not be a problem if I could feature detect window.print, but now browser detecting iOS seems the least of my troubles as this code snippet hopefully demonstrates:
function isPrintSupported() {
if ( window.print === undefined ) {
return false;
} else {
throw 'Maybe?!';
}
}It seems window.print is never undefined, so this function is unusable, but this is breaking the contract of the spec, which says that after a call to window.print “The user agent should offer the user the opportunity to obtain a physical form”.
Many browser vendors don’t make it easy to raise upstream bugs against their browsers, but the open source Firefox has already addressed the bug and merged a patch to fix this. I hope others will follow suit.
Our solution
The Wikimedia Foundation, a non-profit with limited resources. Due to all these problems with the state of web standards relating to printing, it is currently in the midsts of a project to provide a PDF rendering service.
We are creating a web service that hooks up to Chromium — the open source browser project which spits out a PDF. This is quite a complicated project with lots of moving parts. It’s a new service with a maintenance tax that we will have to live with and keep up and running and scale to high volumes of traffic — a cost that would go away if functionality was opened up by a browser vendor. This really shouldn’t be necessary, but it is, and we’re doing it, to help our users share our knowledge better.
Conclusions
Technologies like Service Workers only solve part of the offline picture. We should not consider them the silver bullet for “offline”.
On the other hand, we’ve had print since the beginning, but it’s not clear what the long term future for print is. Does it have a role to play in the future of the web? Is PDF a format that will still be around in the decades that follow? If not, what is the alternative? How will we share web pages without being locked into an internet connection?
I see little activity in this area. Is it the role of the web developer to make use of APIs e.g. URL.createObjectURL to make their content available offline? Is it the role of the browser vendor? Is it the role of the platform? Is this something that can be built on top of the navigator.share API? Google Chrome is now shipped with a feature to take this page offline, yet that doesn’t lend itself too the save and share paradigm. Maybe this is a problem browser vendors should solve, maybe it’s not up to developers, but there’s no clear direction yet, at least from my perspective. All that is clear is there is a gap that needs filling.
PDF seems to be the popular standard for taking content offline, but is it the most future proof of solutions? Would HTML be a better model if it played more into the platform? The TiddlyWiki notebook tool that I used to help build has been doing this for many years. If PDFs are the preferred medium, what does it have that HTML doesn’t? Consistency across platforms? Does that still apply in 2017?
Print medium is important — people still prefer to detach themselves from their devices or are forced to detach from their internet whether it be cost, internet availability or preference (I still refuse to ever read an ebook… but that’s another story). People use the content we create on the web in interesting and unexpected ways, whether that be delivering content to a school or sharing content with a friend over Bluetooth. We cannot rely on distribution via a readily available web.
We’ve built some great foundations in our web standards — media queries are a wonderful tool that allow us to transform our content for use cases, but there still feels like lots of low hanging fruit for making the printed medium more useful.
Is print something we want to keep or discard?
If you’ve enjoyed this article, please try sharing it as an offline PDF or web page with your friends and let me know how that goes for you in the comments…
…
Finally, some asks directed at browser vendors:
- Please remember feature detection when removing features like window.print — make those methods undefined if they don’t do anything. There should be no excuses for browser detection.
- Think about providing and maturing APIs for things you are already providing elsewhere in the browser like print generation and provide better shortcuts to PDF printing.
- Allow for asynchronous behaviour in PDF generation. Alternatively, help give developers the tools to minimise data usage without impairing the usefulness of printed content.

