Failing at pushing a Wikipedia trending API
Failing at pushing a Wikipedia trending API
It was 2016, and a lot of famous people were about to unexpectedly die — including the awe-inspiring David Bowie. I knew within minutes about his passing, but not from where you’d expect.
My phone beeped to tell me there had been a flurry of edits on Bowie’s Wikipedia article. After a brief read of the first paragraph, I realized that Bowie was dead.
That alert in the saddest way possible confirmed a hypothesis that I had recently set out to answer: could I catch trending topics on Wikipedia by looking at the edit activity on articles?

Inception
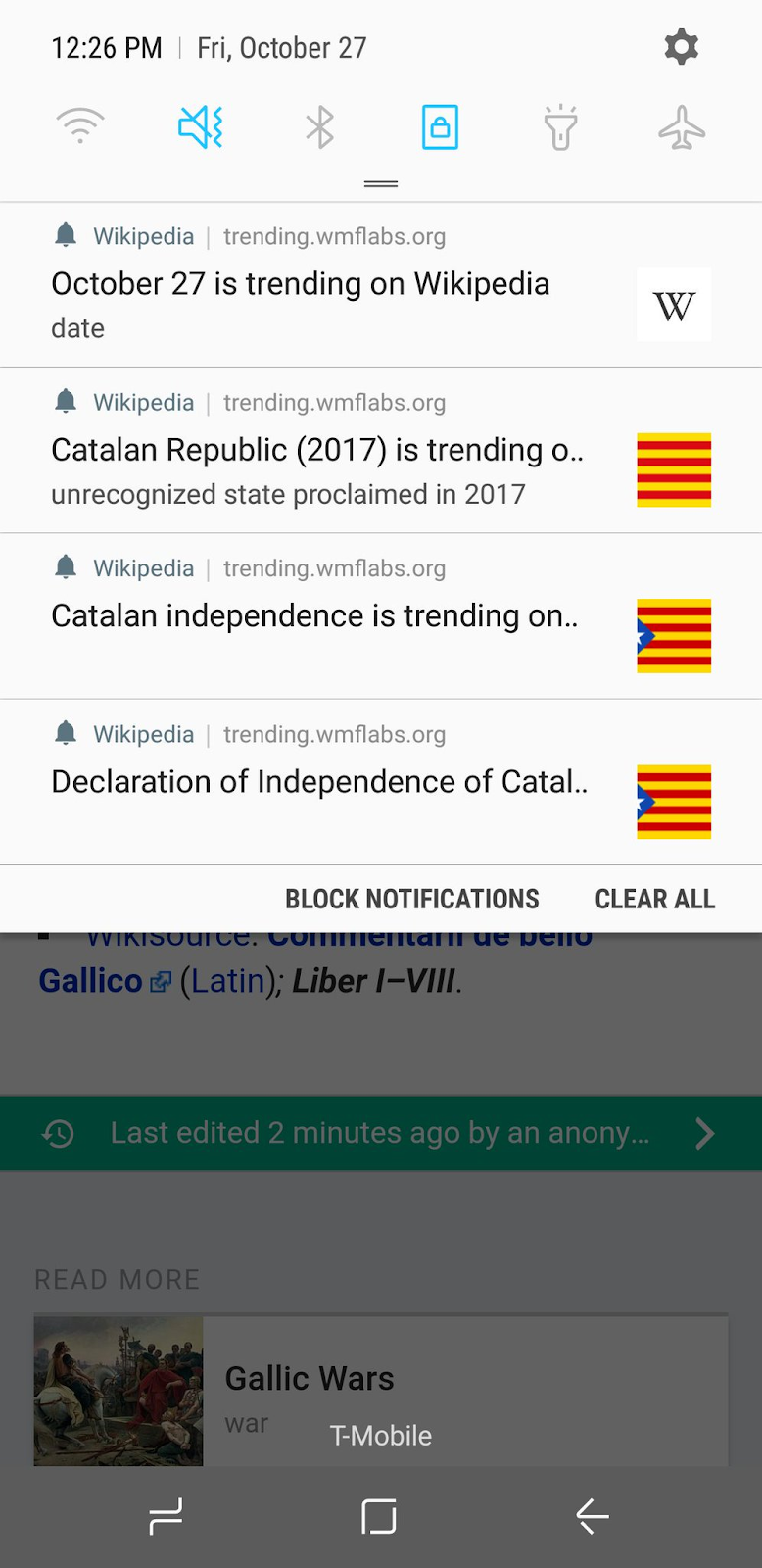
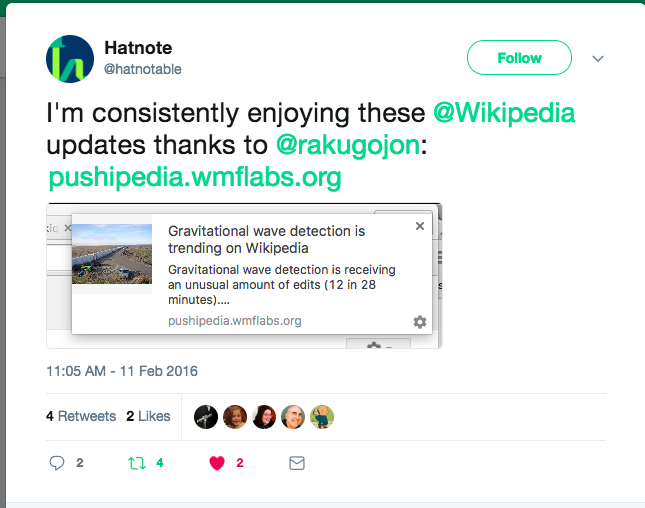
Anticipating an upcoming release to Mozilla Firefox (which would include the web push standard), I had built a service to monitor edits to Wikipedia and send me notifications of unusual activity. My service watched all the edits over the course of that day, using the Wikipedia EventStream API, storing them in an object in memory which I purged periodically based on how many edits were made per minute. I gave each of those articles in memory a trending “score”, and called the early prototype “Pushipedia”.
When the score exceeded a certain value — meaning lots of people were editing a particular article — it would ping my phone.
This became a huge source of news for me informing me about things I otherwise may have missed. Since it’s inception in 2016, I was to learn within the hour of the passing of notable people including Fidel Castro and Carrie Fisher; Singapore’s first ever Olympic Gold medal; important scientific discoveries such as Gravitational wave detection; world events such as Catalan independence the latest movie releases and an extensible knowledge of the happenings in WWE (it turns out many of our editors love the sport).
But you’ve probably never heard of all this, because the project failed.
Iterating on the push
The Pushipedia prototype has gone through many iterations. In 2016, I worked on a reimagined prototype of the Wikipedia mobile website and incorporated the ideas of Pushipedia.
The web version, is still running and has augmented itself into my morning routine (every morning, my wife will ask me “what’s trending”). Seeing the trending articles of the day in such a visible UI however only helped me see the algorithm’s flaws and drove an obsession to make it better.
For example, there were situations where an article would trend even though a single editor would make 90% of the edits. There were situations where two editors would edit war back and forth and things would trend despite no real new content being added. Vandals would make an article trend up, until an article was protected against their edits. Anonymous editors would change their IP address and give the allusion that multiple people were collaborating on a single article. I worked out an algorithm to deal with these difficulties.
Failing to push Pushipedia
My experiments caught the attention of other members of my team, and in 2017 we explored incorporate my ideas into the official Wikipedia iOS app. Instead of the push notification use I envisioned, a decision was to do something far simpler — incorporate the more timely information into the Wikipedia iOS feed.
I was tasked with rewriting the service with this new use case in mind, but the plans sadly fell through after some design research showed that users preferred to view articles based on pageviews. In India particularly, the content was not as familiar. With this use case gone, there was no “customer” and the priority of this work dropped. Struggling to find a home for it and falling into neglect, the service rightly and responsibly got shut down.
I was of course disappointed about this. I’m sure many developers have experienced the pain of building something you love only to see it never see the light of day. Failure sucks, but failure is normal. Everyone fails.
I could have dwelled on this, but this wasn’t the first failure I’ve experienced. Back in 2015, my team attempted to build out a reading list feature for end users that despite being popular with readers was badly received by the editing community and eventually shut down. I was able to appreciate why this failed — ultimately this project was too ambitious; underestimated the importance of editor buy-in; and didn’t prioritise moderation of public reading lists. Based on these lessons, this year, we recently successfully launched a private reading list feature to our mobile apps.
Failure has been an important lesson for me during my time at the Wikimedia Foundation. Failure is normal. What’s important is how you learn and respond to it.
Finding a home
Despite its failure and understanding why it failed — an unclear use case; more important initiatives; not enough available resourcing — I still believe in this project.
Currently Wikipedia is very much seen as a secondary destination that you get to from Google or Twitter but this trending endpoint gave me hope that it could be much more. I couldn’t find it a home in the Wikimedia Foundation and in our core products, but as a volunteer I could continue to work on this tool.
I believe the Wikimedia movement can be a good compass for what’s important to the world, especially in a time of “fake news”. It’s not perfect — during the 2016 Olympics I noticed many male dominated events trended whereas the female equivalent didn’t and at times in 2016, the buzz of my phone telling me I had a push notification made me anxious wondering which of my heroes had died this time and I was scared to look at it. It was a rollercoaster with highs and lows, but most of the time it was positive and it was one of the things I was more proud of building.
Nevertheless, I was given lots of feedback by users. One of the main sources of feedback was that it was not always clear why something was trending. At one point, something unusual was trending — BBC 100 Women 2016 — while potentially not “breaking news” it was interesting to know this was happening and with a little investigation I discovered an editathon was happening, however to another user it was just noise. One of my guinea pigs playing with the service complained about the constant vandalism they were getting told about, while another — a regular editor — told me they loved the fact they got vandalism and could jump in and fix it. You can’t make everyone happy.
I think this is why it never found a home — there are too many things you could do with such a service — just like there are so many rabbit holes you can go down while reading Wikipedia. One person’s joy is not another, so while someone may enjoy spending hours on Wikipedia reading about World War II, maybe another wants to read about all the television shows on Netflix. For this purpose, I think it needs a special home.
IFTTT.com is a free web-based service that allows non-developers to chain services across the web to creatively create new services. As of today, you can now use the Trending service as one of the many available Wikipedia services. The service can be linked to email, Twitter, Pinterest and all sorts of other services — including smart devices. You can make a light bulb flash every time the Deaths in 2018 page trends or receive a push notification or email for all unusual edit activity.
I’m excited to hear what creative use cases users are able to use it for and hope that those who do will find the joy that I have long enjoyed through it.

Maybe with use, it will find somewhere more permanent, but out of my failure, I hope others can find the joy that is the trending rollercoaster. If you love something let it go, hopefully it will go somewhere even higher.
Developer afterthoughts
To provide more context for the service, here I will go into a little more detail about the interesting technical aspects of this project.
Algorithm
The algorithm for the trending service, was mostly through trial and error through examples I found. If I could go back in time, I would probably have fun “machine learning” it, but at the time, it was a fun distraction to immerse myself in the “pulse” of Wikipedia’s many editors and get close to what was driving them to edit. In a way, I felt like I was tapping into the heartbeat of a global population.
I made various tweaks to the algorithm over the years on a variety of variables:
- Number of edits was ultimately one of the more important variables. An article needs lots of them in a given timeframe to trend.
- Number of editors was equally important. The more people that collect around an article, the more notable it might be.
- The ratio of named to anonymous editors it was also essential for the ratio of users who made an edit with an account outnumbered those without one (it turns out when something important is happening there is credibility in having your name associated with “breaking” the story).
- Not only were number of editors important, but I needed to inspect the distribution of edits and work out a bias. For instance, a single editor making 15 edits and two other editors making a single edit each was less notable than 3 editors making 6 edits each.
- The number of bytes that changed hands during a series of edit transactions helped me weed out a lot of the vandalism that was occurring (if a vandal removed a whole section of content and another editor added it back verbatim the bytes changed was zero).
- Reverts were equally important, but annoyingly these are not easily countable — a revert is just a normal edit in the software that powers Wikipedia, so relying on de-facto standards in the summary message that accompanied an edit was the best I could come up with. I also scanned this message for key word indications that vandalism was going on. If this happened I incremented a flagged edits counter.
- Number of page views — I experimented briefly with looking at the number of page views an article had the day before. I figured if something was being read the day before, people were already aware of the article and it was no longer something that could be considered trending
The algorithm I ended up with is immortalized in my wikipedia-edits-scorer GitHub for those interested and as with all our software is open source and free to use.
Midway through building my algorithm I was pointed on Twitter to some research that was done in 2013 and 2014 by Thomas Steiner which explored the theme of using Wikipedia for breaking news stories. This research explored many of the same themes and visualizes such changes in the Wikipedia Live Monitor. The code for which is also available on Github. I wish I had known about this earlier as it would have saved me much work— a reminder to leverage your social networks early in your thought process!
Planning
As developers, it’s important we scratch itches and follow our interests and write code. That’s when the most interesting things get built!
Looking back, however, I wish I’d made use of a lot of that energy and enthusiasm to do the non-technical work such as talking to product owners and drafting product proposals in time for annual planning.
Scaling for Wikipedia’s traffic
It’s never good to deploy a prototype, so when the iOS team asked to incorporate the service into their app, I started again with a greater attention for performance, scaling to Wikipedia’s traffic and reliability.
Using the node libraries I’d already written, it was reasonably low effort but there were complications in how we scaled the service and how data was collated.
For my prototype, to allow for reboots of the server, I cached activity periodically throughout the day in a JSON file using a level-up store. However, when scaling for production, given we were running concurrent services on different machines, managing a cache in a single file on a single machine was not going to work. Instead we were able to replay an entire 24 hour period of edit events via Apache Kafka. We started small, only replaying 4 hours of editors and found that even with all the edits occuring on Wikipedia, we were able to replay a 24 hour period.
In my prototype, I used the Wikimedia EventStreams service. If you’re interested in working with this data or any of the libraries I’ve written — and provided you are not a top ten website — the EventStreams service should be more than enough for your needs.

