Why all developers should do their chores
Why all developers should do their chores
How technical debt can become a shared responsibility
MediaWiki, the software that powers Wikipedia, is afflicted with the beautiful dichotomy that plagues many open source projects — it was built over a decade ago with lots of enthusiasm and many fantastic ideas, but with fewer concerns about code quality and long-term maintenance.
It should not come as a surprise that MediaWiki, while powering one of the most important resources on the web, has also accumulated significant amounts of technical debt. To cope with this, my team at the Wikimedia Foundation — the organization now charged with stewarding MediaWiki — found a ritual that allowed us to decrease the numbers of errors and regressions, improve our efficiency, maintain a certain level of quality, and evolve and bond as a team. Here’s our story.
Working at scale
My core team consists of a tech lead (myself), a product owner, an engineering manager, a designer, and four other developers. The eight of us maintain the entire Wikipedia mobile website, the page previews feature that we shipped to desktop several months ago, and other bits of critical but relatively stable infrastructure. We’re actually spread quite thin and keeping on top of problems can be pretty difficult.
Even so, I think we do an incredible job.
Infrastructure and tooling
Since Wikipedia’s conception in 2001 (17 years ago!), the supporting infrastructure has gone through many positive transformations. It was only in 2009, with a new strategic plan and growth of the Foundation, that the infrastructure to support our MediaWiki based production started to become fleshed out. Integration tests (Selenium) were added (conceived in 2012); a production-like beta cluster was added (2012); Logstash was added for server-side error reporting; a performance team was created to set up infrastructure for monitoring and improving performance (WebPageTest and tooling to collect NavigationTiming data from real users); and we switched from Bugzilla to Phabricator to improve how we curate bug reports.
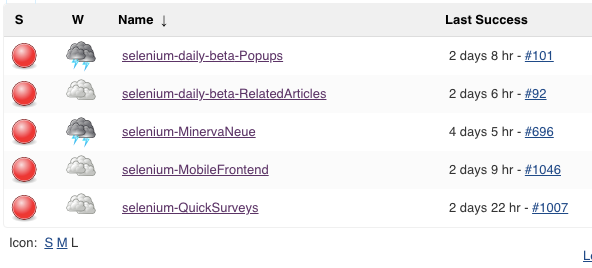
This tooling has been essential for us to measure the health of the site and keep the team accountable. The tooling is by no means complete. Notably, there is no infrastructure for collecting of client-side errors, although Sentry has been proposed.
Infrastructure is only good if you look at it
Despite the fact we have all these tools to aid us to maintain quality, the tooling is only good if you use it. In the early days, if browser tests failed, emails would be sent to point people hoping that they would deal with them; Logstash errors would only go noticed if they caused trouble during deployments or someone had taken the initiative to look at them; it was up to bug wranglers to make sure bug reports got to the right people; and up to the performance team to tell product teams that their work was causing unacceptable performance regressions.
It would be great if failing browser tests blocked deployments, but they don’t.
It would be great if error spikes in server-side errors automatically created a bug and routed it to the right person, but they don’t.
When you work for a non-profit maintaining a site at scale and trying to live up to its values of openness and transparency, one of the big downsides is that you can’t afford every single tool offered to you and even if you could you don’t necessarily have enough people to stand it up and maintain it.
These kind of problems were causing a lot of stress to people in my team as our team cares a lot about our product and our output.
For a period of time my team often felt:
- vexed when nobody had noticed a regression in production caught by our browser tests.
- concerned by any unusual and un-investigated errors in Logstash.
- inadequate when we began drowning in triaging tickets from community members
- upset about all the unknown client-side errors that our users were surely experiencing but not able to tell us.
During one of our team retrospectives, (which we have every two weeks), we shared these frustrations and why we cared about them. Finally, we talked about ways of sharing that burden.
Enter the chores list!
Our scrum master, Max Binder, proposed a solution back in December 2016 (2 years ago!) that had been enjoying success in our iOS team (originally conceived by Josh Minor).
The solution was to define a list of things that were important to the team, which we named the Chore list. The plan was each team member would take turns to go through that list daily to check things in the list were of the standard we expected. A time-box was set up to set the expectation that we shouldn’t spend too long going through that every growing list and to help us prioritise what needed to be looked at at any given time.

Executing a chores list
When we began the experiment, we used a mailing list to report on the current state. Many of these emails never got replies, so the sender was never clear if someone read and digested them, but when we brought this up in our team retrospectives what we actually found was people were using them and finding them useful!
When there were conversations on the emails, these conversations were quite useful, even if it was just an opportunity for our product owner to understand the severity of the latest regression and understand its priority or to explain a spike in a graph we were seeing. Sometimes the chores subject was something as simple as “Chores 13th July — everything is awesome EOM”.
The doing of chores, like any list of chores, has required discipline and engagement from the team.
There have been many days where people “forgot” or “didn’t have time”. We have found that flagging (without blame!) this kind of neglect in team rituals such as retrospectives and stand-ups has helped remedy the problem quite quickly. The important thing is that as a whole the team sees the benefit in this ritual and is keen to keep the ritual alive.
It’s been really important for the team to adapt as our responsibilities have shifted and we’ve encountered new experiences. On one occasion our analytics team flagged to us that we were causing a large chunk of errors that was clogging up their analytics pipeline. They pointed us to a graph measuring errors that we didn’t know existed. After fixing this problem, we added a new chore to the list to check that exact graph to make sure it didn’t happen again.
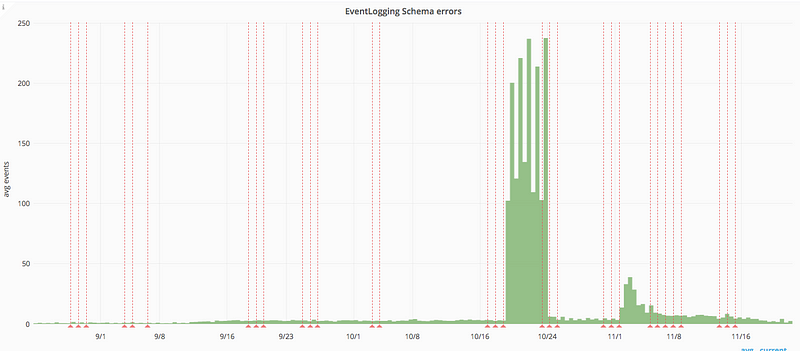
Even our chores themselves have got maintenance — in particular, many of the queries we use to identify tasks we are responsible for working on; identify code that needs reviewing and identify errors that we are on the hook for fixing have been tweaked and improved for the next person.
The process also got maintenance. The email format we used changed in various ways over time until eventually we settled on a wiki page.
With email, we found several benefits:
- it was useful to pull in people from other teams
- we got to send each other GIFs
However we faced challenges with some basic human problems.
- We struggled to agree on whether the subject header date format should be “Chores: Thursday, 16th March”, or “Chores 16th March” or “Chores 16/03/18” (you get the idea).
- The lack of a consistent subject header, made it hard for us to access historical information
- This also made it hard for us to set up the appropriate email filters for a daily email.
- Half the team really liked emails laid out in rich text format tables while the other half wanted plain text.
These small problems, aside, more crucially, we were noticing larger problems.
- We were duplicating efforts in debugging the same bugs our browser tests had uncovered
- Certain chores were being neglected for weeks without us realizing
We kicked ourselves a little, when we realized that switching to a wiki format removed all of those issues. We maintained a single email thread to allow the benefit of side chat and GIF usage (very important!) and in addition to this we got to dog food our products.
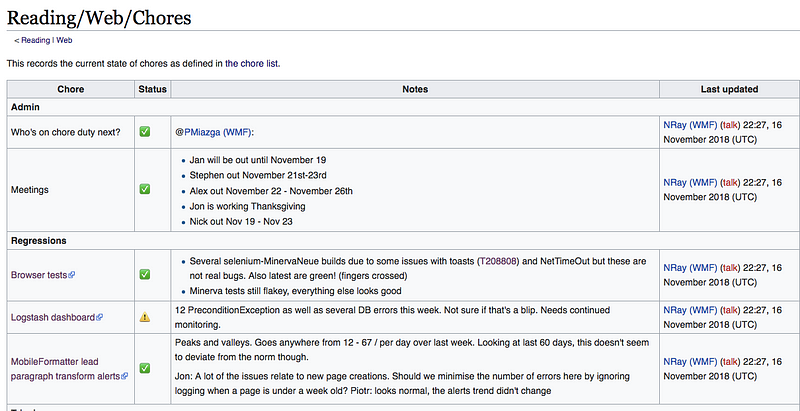
Why every team should have its own chore list
One of the greatest benefits of sharing this load has been the shared responsibility and awareness of what quality means in our team.
Two years later, we still use this list, but the list like any good wiki page is no reflection of its original state, having had over 100 edits from a variety of team members.
Some of the measurable benefits of having a chores list include:
- When we started out there were hundreds of server-side errors being experienced by users in obscure parts of our interface. Now, two years later, it’s quite rare for one to show up there, which feels good.
- Bugs are rarely making it to production (we’ve experienced less emergency hot fixing)
- We’ve become more aware of how banners from our fundraising team and volunteers severely impact our performance (e.g. this bug)
- Our backlog has shrunk from around 400 to 153 open bugs thanks to a shared responsibility in triaging.
While less measurable, the shared responsibility has had a positive impact on the team dynamic.
It’s been beautiful to watch the team self-organize around defining code quality.
Our designer, added a chore to help prioritizes and organize design the backlog. After we launched a PDF rendering service, one of our engineers added a chore to monitor npmjs.com for new package releases. After several rounds of vacations, meaning chores were not being done, the team in retro decided to add a chore to inform the group who was next. This made it transparent not only that chores were not being done, but who was not doing them to the rest of the team.
If your software development team doesn’t have one already, I think a chores list is a great and inexpensive way to get your team thinking constantly about quality and constantly striving to improve. Having one has sure helped mine.

Footnotes
Our chores list is entirely public, so feel free to dig into all the interesting data we monitor, including the grafana dashboard. Let me know in the comments if your team does (or is thinking of doing) something similar. I’d love to hear from you!

